OpenAIが新しい画像生成AI「DALL·E 3」を発表しました
読み方は、DALL·E 3と書いてダリスリーと言います

DALL·E 3は、テキストから画像を生成することができ、ChatGPTとのシームレス(継ぎ目のない)な連携が特徴で、ChatGPT上で使うことが出来ます
ユーザーは、ChatGPTにアイディアを入力すると、プロンプトの自動生成を行ってくれたり、思い通りのが画像に近づけるための調整の相談を行うことが出来る様です
※以下はOpenAIが発表した原文です
When prompted with an idea, ChatGPT will automatically generate tailored, detailed prompts for Dall-E 3 that bring your idea to life
If you like a particular image, but it’s not quite right, you can ask ChatGPT to make tweaks with just a few words.
Open AI社
これにより、ユーザーのアイディアや想像をより繊細かつ正確にビジュアルコンテンツに変換することが可能になります。
OpenAIはDALL·E 2という画像生成AIを公開していて、DALL·E 3はそのアップグレード版となります

ChatGPTで画像生成AIを行えるDALLE 3
DALL·E 3は、テキストから画像を生成する人工知能(AI)ツールの次期バージョンで、生成AIチャットボット「ChatGPT」に組み込まれています。
ChatGPTを利用して生成画像の作成や、調整ができるようになりました
2023年9月時点は、リサーチプレビューの段階だが、有料版のChatGPT PlusおよびEnterpriseの顧客には10月より、API経由およびLabsでは2023年10月に公開されました
【DALL·E 3】 ChatGPTでプロンプトを忠実に再現できる機能
DALL·E 3は、先代の「DALL·E」(2021)および「DALL·E 2」(2022)をベースに更に発展させ、より高度で精緻な機能とアーキテクチャ(AIの内部構造)を実装した画像生成AIです
画像生成AIを使った人は経験すると思いますが、初めてプロンプトから画像が生成された時には、驚きを感じますよね
しかし、思い通りの画像を生成しようとすると、キレイな画像は作れてもイメージした画像は作ることの難しさを感じ始めます
テキスト(プロンプト)から作るt2i(txt2img)には、さまざまな構造的な事情があります。
生成プロセスを実行しないと、どのような結果が得られるのか予測が難しく、この不確かな性質から、t2i(txt2img)は「呪文」とも称されています
この問題を解決するためにDALL·E 3では、ChatGPTの機能を利用することで、ユーザーは自分がイメージした通りの画像をAIに生成させる手助けを受けることができます。
これにより、ユーザーの具体的なビジョンやアイディアを、AIが正確に理解し、それを基にした画像を生成することが可能となります。
ChatGPTとのシームレスな(継ぎ目のない)連携
上記の理由からChatGPTとの統合により、ユーザーはプロンプトの作成や精緻化がより効率的かつ簡単になります。
これにより、ユーザーの要望をより正確に反映したビジュアルコンテンツの生成が可能になります。
この新バージョンは、「Midjourney」や「Stability.ai(Dreamstudio)」などの他のサブスクリプション型画像生成サービスに比べ、顕著な利便性と機能性を備えています。
StableDiffusion(SDXL)とDALL·E 3の比較は?

オープンソースのStableDiffusionや、新しいStable Diffusion XL(SDXL)との、比較はどうなのかな?
それぞれの画像生成を使ってきた個人的な意見ですが、好みはあるものの上手く住み分けが出来るのではないかと思います
初期の画像生成AIが登場した時よりも、さまざまな意見や倫理基準と権利の確保が求められた結果、各画像生成AIはバージョンアップの際に改善がされてきました
StableDiffusionも例外でなく、諸問題が起こる様な画像生成を行えなくなってきています
ただ、StableDiffusion(SDXL)は、web上で動くサブスクリプションのサービス(DALL·E 3など)よりは、自由度は高いかと思います
例えば、Midjourneyですとブロック対象のプロンプトが入っていた場合には生成が行われない様になっていましたが、StableDiffusionですとブロックはされないが、表現がマイルドになりつつも生成は行えます
また、StableDiffusionはユーザーによる追加学習させることが豊富にできるので、コントロールは難しくなるものの好みの画像を生成しやすい
DALL·E 3は、言語モデルの入ったマルチモーダルの生成AIなのでプロンプトの作りやすさ、ユーザーの糸の反映しやすさがあげられます
画像のテイストは、それぞれの特徴があります
詳しくは次の項目で、お話します
【DALL·E 3】画像生成AIの倫理基準と権利の確保
DALL·E 3は、前モデル同様に、暴力的、成人向け、憎悪的なコンテンツの生成、特定の人物やキャラクターの描写、また存命のアーティストのスタイルの模倣を拒否する設計となっています。
OpenAIはさらに、AI生成画像の権利問題に対応するツールをテストし、権利処理の透明性を確保するための取り組みを行っています。
自分の生成した画像も、生成AIの学習に使われることを防ぐ仕組みも用意されています
他の生成AIと比べて、画像生成AIは企業さまが導入を見送っているように感じます
ChatGPTなどの言語生成AIは企業さまも、国の機関も導入を始めてるけど、画像生成AIは動きが少ないですね
一部の企業さまは、写真集や、雑誌の表紙に使ったり、webサイトのサムネイルにも使われることはありますが、まだあまり見かけません
これには、権利問題や元データの所在が明確でない所の問題に行きつきます
画像生成Iにおいては、生成された画像やコンテンツの出所や元データの所在が明確でない問題が存在しています
DALL·E 3は、AIによって生成されたコンテンツの出所を特定するための分類子を試験しているようですね
ディープフェイクの特定だけでなく、アーティストの作品が許可なく訓練モデルの学習に利用されたかどうかを追跡することは重要な意味を持ちます
著作権や訴訟リスクを回避し、安全な商用利用を可能にするための取り組みとして以下の取り組みをしています。
- Adobe社はFireflyモデルの初期トレーニングにAdobe Stockの画像
- オープンライセンスのコンテンツ
- 著作権の切れた一般コンテンツを使用しています。
これにより、営利目的での利用も安全かつ合法的に行えるよう配慮されています。
また、Adobe Fireflyは、生成したコンテンツに対して、条件に応じてアドビから知的財産の補償が提供されるよう設計されています。
APIを使ってブランド独自のスタイルやブランド言語でコンテンツを生成し、自動化を推進することもできます。Adobe Fireflyは、安全に商業利用できるように設計されており、Fireflyによるワークフローで生成したコンテンツによってはアドビから知的財産(IP)の補償を受けることができるため、企業は安心して本ソリューションを組織全体に導入することができます
https://www.adobe.com/jp/news-room/news/202306/20230608_firely-and-express-to-enterprises.html
DALL·E 3でクリエイティブな表現の可能性
DALL·E 3は、ユーザーのテキスト入力を深く理解し、そのニュアンスやディテールを精緻に反映したビジュアルコンテンツを生成します。
イラストが不得手な人でも、このツールの使用により、自らのアイディアやビジョンをビジュアルアートとして表現することができます。
そして、このツールの発展により、ビジュアルアートの新しい形が生まれ、クリエイティブな表現の領域が広がることが期待されます。
DALL·E 3以外でも、ChatGPTには、新しい機能が加わることが発表されています。
画像認識や音声機能のが大幅に強化され、ChatGPTと音声でのやり取りが可能になり、会話している様にコミュニケーションが取れる様になるようですよ
StableDiffusion WebUIなど画像生成AIに関するリンク集

StableDiffusionに関する以下のコンテンツとコラボさせて頂いてますので、ご興味ありましたら覗いてもらえたら嬉しいです




最後に、お知らせをさせてください
StableDiffusion WebUI v1.6.0(随時更新リサーチ中)
- StableDiffusion WebUIバージョン1.6.0リリース速報まとめ
- 【SDXL1.0のVAE】StableDiffusion WebUI v1.6.0 導入&設定方法
- StableDiffusion WebUI ver1.6.0「VAE」切り替えを便利なインターフェイス
- ControlNet ver1.14バージョンアップSDXLに対応…しかし
StableDiffusion WebUI や拡張機能のダウングレード
StableDiffusion webUI基本設定
- StableDiffusion WebUIをローカル環境で使う設定のやり方♪
- StableDiffusion WebUIバージョンアップ方法。更新手順や注意点
- StableDiffusion WebUIバージョンの確認方法
- 【操作画面の解説・txt2img】分かりやすくパラメータの使い方を説明
- 【画像生成AIイラスト】VAEインストール方法と便利な使い方
- 「VAE」かんたんに切り替えするインターフェイス
- 【日本語化】StableDiffusionWebUI インターフェイス設定方法。
- 大きく、キレイな画像を出力する方法Hires.fix使い方。解像度アップ!
- 操作画面の5つのボタン解説
- 【X/Y/Z plot】使い方。プロンプトや設定を調整し比較してみよう!
- 【img2imgインペイント】画像生成AIイラストを修正/inpaintのパラメータ
- 【学習モデルの追加と変更】かんたん切り替え
- StableDiffusion WebUIバージョン1.3。LoRAを使う方法
- 【まとめ】画質が悪いを改善する7つの機能の使い方!
- 【StabilityMatrix】StableDiffusionWebUI簡単インストーラー
【学習モデル・checkpoint】
- 【実写系学習モデル・3選】写真の様なリアルな美少女が作れるモデルまとめ
- 【BracingEvoMix】日本人風の顔に特化した最新学習モデル
- 【BeautifulRealisticAsiansV5通称BRAV5】
プロンプト
- Stable Diffusionプロンプト(呪文)に関しての書き方。
- 【画質を上げる・画質に美しく芸術性を持たすプロンプト】呪文の書き方
- 【Tag complete】プロンプトのコツを掴める入力補助機能。
【ControlNet】
- 【ControlNet】使い方とインストール方法。画像生成AIイラストに便利な神機能。
- 【ControlNet-V1.1206】最新バージョンアップデート&モデル更新方法。
- 【ControlNet】不具合?表示されない…反映されない時には?
- 骨(棒人間)を使い、思い通りの姿勢をとらせた方法。
- 原画の絵と同じ姿勢(ポーズ)のAIイラスト生成のやり方♪
- AIイラストから線画を抽出する方法♪
- AIイラストを手描きで修正し、生成するやり方♪
- 【ControlNet】自作の線画イラストを画像生成AIに色塗り(ペイント)させる方法
- 自作の線画イラストをAIイラストに色塗り(ペイント)させる方法♪
【その他 拡張機能について】
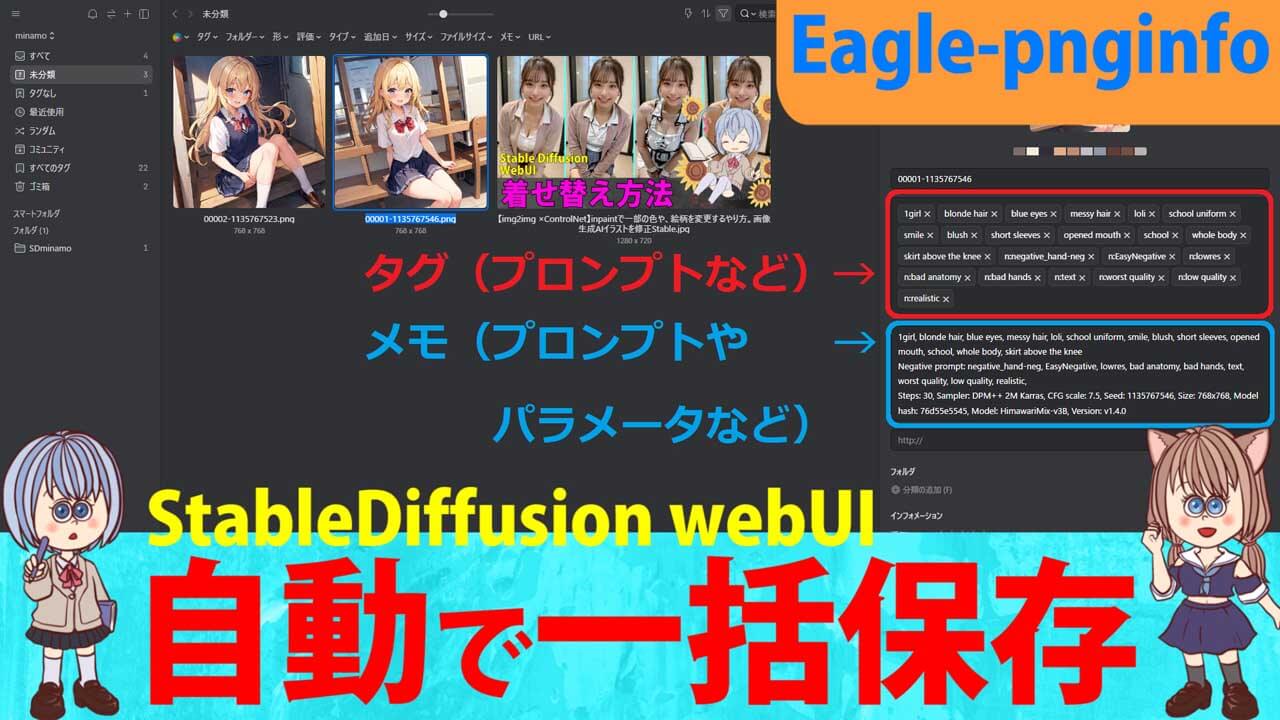
- 【Eagle-pnginfo】画像やプロンプトを自動で一括管理できる拡張機能
- 【eagle】画像管理おすすめアプリ使い方
- 【eagle】公式サイト
- 【EasyNegative v2】導入&使い方♪設定方法
- 【EasyNegative V2】反映されないときには?原因と対処方法
- 【EasyNegative V2】【LoRA】にサムネイルを付ける方法
- 【LoRA】画像生成AIの追加学習データの使い方。
- 【Dynamic Prompts】ダウンロードとインストールの設定方法と特殊構文の使い方
- SDXLでも使える?【ADetailer】手や顔の崩れを自動できれいに修正できる拡張機能
- 【ADetailer】Detectionで検出範囲を設定し複数人を検出。パラメータを解説